Introduction to SQL
An overview of the basics
📖 Rules of engagement
- The content in this presentation is not for distribution as content has not been vetted by our benevolent overloads.
- The purpose of this document is to guide discussion, elicit feedback, and show you new ideas. The more you lean in, the more you win!
- As a follow up on the last point, you can and should ask questions. The content I’ve put together is a means to a conversation.
- You will need to have installed DB Browser for SQLite, link to download here.
- Learning is a continuous journey, no one person’s journey is linear. Be kind. Be patient. Be inquisitive. 🧘
Where are we going today? 🗺️
The goals today are to:
- Define SQL and the type of databases it supports
- Convince you why databases matter and why SQL will make your life easier
- Expose you to some fancy new vocabulary to talk about databases
- Code a little SQL
- Point you in the direction of other resources (should this whet your appetite for learning 🤓)
🤔 What is SQL?
- S-Q-L or “sequel” stands for Structured Query Language
- It’s a standard programming language used to “talk” to a database1
- Enables user to query, update, delete, and insert data
- Used as the front-end of many database systems (MySQL, PostgreSQL, Oracle, SQLite2, and many more) for database management and (some) data analysis3
- What do the aformentioned database systems have in common? They are relational!
Quick Aside: Relational databases 🏃
- A relational database is one that stores and organizes data in tables, where each table is make of rows and columns
- Each table represents a different data set (e.g., people, locations, people in those locations) and the tables are linked by relationships
- Relationships are: “defined between a pair of tables. All other relations are built up from this simple idea: the relations of three or more tables are always a property of the relations between each pair.” (Wickham et. al, 2018).
- Tables relate to each other by keys (commonly).
Have you worked with a relational database? 🤔
BTW: From here on out, when I talk about SQL and databases, you should assume these are relational.
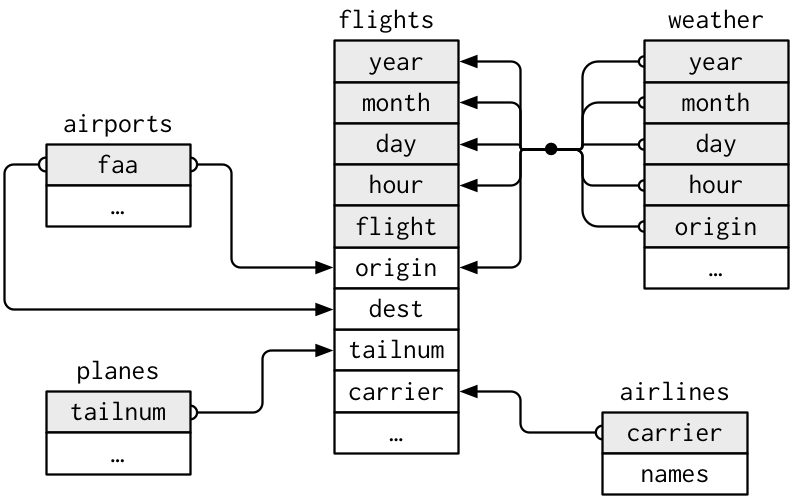
🎨 Relational database schema1

Why put data in different tables?
Key relational database concepts 🔑
- A database can be run locally (e.g., SQLite), but many are hosted in dedicated database servers1 (e.g., on-prem vs. on-cloud database servers).
- A database server can contain many relational databases.
- A relational database is a collection of tables.
- Tables are two-dimensional heterogenous data structures with rows (observation) and columns (variables).
- Relational databases use SQL to execute limited mathematical and summary operations.
- SQL is very good at combining information from several tables.
🤔 When do you need a database?
- When you need to support multiple users accessing and modifying data concurrently and in a controlled manner
- When data changes on a regular basis
- To store, organize, and manage large amounts of data efficiently (e.g., think of the schema)
- To support rapid queries with no analysis1
- To support other software applications, such as web interfaces that depend on persistent data storage2
What am I missing? 🤔
Ways to use SQL1 👨💻👩
- GUI interfaces (e.g., MySQL workbench for MySQL, DB Browser for SQLite, among others): Easier than most 😒
- Console commands (e.g.,
mysql -user foo -p bar): Harder to learn 😫 - Through interfaces to other programming languages (e.g., SQLAlchemy in Python, dbplyr in R, among others): Hardest to lean2 😭
Don’t despair… we all start somewhere! 🌱
In fact, we will start now! 🚀
💪 Time to get to work
We are going to dive head first and write some SQL to engage with a relational database using SQLite.
Our goal here is to answer one big(ish) question and some supportive questions:
- What does out data (more specifics in a minute) look like?
- How much?
- What is the unit of observation?
Meet: NYC Flights ✈️
- The database contains information about all flights that departed from NYC (e.g. EWR, JFK and LGA) to destinations in the United States, Puerto Rico, and the American Virgin Islands) in 2013.
- It also includes useful metadata on airlines, airports, weather, planes.
- Have provided it as an
.sqlitefile.
A codebook would be VERY useful…🤔
📖 Codebook of tables1
flights: all flights that departed from NYC in 20132weather: hourly meterological data for each airportplanes: construction information about each planeairports: airport names and locationsairlines: translation between two letter carrier codes and names
This will do, for now…🤷
We will focus on exploring the flights table 🔍
Codebook of flights table 📖
year,month,day: Date of departuredep_time,arr_time: Actual departure and arrival times (format HHMM or HMM), local tzsched_dep_time,sched_arr_time: Scheduled departure and arrival times (format HHMM or HMM), local tzdep_delay,arr_delay: Departure and arrival delays, in minutes. Negative times represent early departures/arrivalscarrier: Two letter carrier abbreviation. See airlines to get name.flight: Flight number.tailnum: Plane tail number. See planes for additional metadata.origin,dest: Origin and destination. See airports for additional metadata.
…plus more.
Start your engine 🏁

🔍 What does out data look like?
Try this!
Let’s break down the SQL code:
SELECT: Specifies the variables we want to return.- We use
*, which tells the database that we want all the variables in the table. If we only wanted specific variables, we would use the column names separated by commas instead of*(ex.SELECT year, period_name, ...).
- We use
FROM: Identifies the table,flights, from which we want to retrieve the data. Most queries will begin in this fashion, describing the column(s) we want to return (SELECT) and their corresponding table(s) (FROM).LIMIT: Restricts the number of rows that are displayed. We confine the output to10rows in this query.
Keep in mind ⚠️
- Note that the query is sensitive to the order of the commands, as we start with
SELECT, then inputFROM, and end withLIMIT. - The SQL keywords are case insensitive (
SELECT,FROM,WHERE, etc.), but they are often written in all caps. - Spelling matters. Spacing matters. Computer “think” differently…
#️⃣ How much data?
Let’s break down the SQL code:
- The
COUNTcommand counts the number of non-missing rows of the variable(s) specified. When we useCOUNT(*), it counts all the rows in our data set.
So how much? With 336,776 observations it is a good things we didn’t try to look all at once. This is why we usually include LIMIT when exploring.
Unit of observation 📏
The unit of observation refers to the type of entity or object about which data is collected. This could be a person, a organization, a state, or any other entity that is the focus of data collection.
Recall the description of this table:
- flights: all flights that departed from NYC in 2013
Let’s look at the table once more:
Looks like the flight variable, which denote the flight number for flights departing NYC.
🔍 Deeper dive
Try this:
Let’s break down the SQL code:
DISTINCTreturns only unique values of the variable(s) specified. RunningSELECT DISTINCTvariable would return only unique values ofvariable.
That’s a lot of different flight unique identifiers! Do any repeat?
Even deeper dive 🔍
Try this:
Let’s break down the SQL code:
- While
DISTINCTreturns unique values of the variable(s) specified,COUNT(DISTINCT variable)outputs the number of unique values ofvariable.
Notice that you have fewer unique flight values that total rows in the table. Why?
To me it indicates that flight alone does not fully define the data. Perhaps there is a combination of flight, date, and time.
Next time, we will cover time! ⏰
🔙 Recap
Try to answer:
- What is SQL?
- Why do we use it?
- What is a database?
- What databases work with SQL?
- When do databases shine?
Resources 🔗
SQL:
- w3school’s SQL tutorial
- codecademy’s SQL tutorial
- Data Management with SQL for Social Scientists
- SQL Basics Cheat Sheet
- Google (e.g., “how do i … in SQL with …”)
R:
❓Questions?

Your HW 🫨
- Find a data set with two or more tables that we could explore using SQL
- (Optional) Start building a schema! Don’t know how? Check out drawio.
![]()
For Internal Use Only