Introduction to SQL
Aggregating and Grouping Data
📖 Rules of engagement
- The content in this presentation is not for distribution as content has not been vetted by our benevolent overloads.
- The purpose of this document is to guide discussion, elicit feedback, and show you new ideas. The more you lean in, the more you win!
- As a follow up on the last point, you can and should ask questions. The content should be a conversation, not a monologue.
- You will need to have installed DB Browser for SQLite, link to download here.
- Learning is a continuous journey, no one person’s journey is linear. Be kind 🤗. Be patient 🧘. Be inquisitive 🤔.
Objectives 🎯️
- Apply aggregation functions to group records together.
- Filter and order results of a query based on aggregate functions.
- Employ aliases to assign new names to items in a query.
- Save a query to make a new table.
- Apply filters to find missing values in SQL.
First, a bit of a reminder
(Making sure you didn’t forget!)
🧩 The Basics
- Using the
SELECTcommand allows you to choose the fields that you want returned from your database
FROMpinpoints the table that you want to pull from
Tip
Don’t forget to end your query with semicolon. 🙃
The Basics (Plus) ➕
- Databases can also be filtered using
WHEREto only return certain criteria
SELECT desserts
FROM things_in_not_supposed_to_have
WHERE (calories <= 1000) AND (has_chocolate = TRUE);- You can also sort the results of your queries with
ORDER BY
- Comments are you friend 👬
/*
This is how I query my table of desserts based on some my sophisticated criteria
which minimizes calories, prioritizes chocolate, and orders by regret after
eating.
*/
SELECT desserts
FROM things_in_not_supposed_to_have
WHERE (calories <= 1000) AND (has_chocolate = TRUE)
ORDER BY regret_factor ASC;Back to Regular Programming 📺
🏁 Start your Engines

Meet the Data 👋
CSG Justice Center’s National Reports Database:
- Repository of data from commonly used data sets, including UCR, NIBRS, BJS, ACS, among others
- Updated regularly as data become available
- We will use data from the Vera Institute of Justice on people in prison.
Let’s take a look:
Important
Tables with spaces in the name should be wrapped in [ and ].
➕Aggregating Data
- Aggregation allows us to combine results by grouping records.
- To do so, we will need to rely on SQL functions such as:
COUNT(): returns the number of rows that matches a specified criterion.AVG(): returns the average value of a numeric column.SUM(): returns the total sum of a numeric column.
- Begin by finding out how many observations are present in the
Vera - Prison Numbers by State-County - 1990 to currenttable:
Challenge⚡
Write a query that the population for the prison population for the state of California in 2015?
You got time ⏱️, but not too much.
👥 Group By
- Sometimes it is useful to break down our data into smaller, more manageable groups, before aggregating. For example, what if we wanted to calculate the prison population for a given state for all years.
- The
GROUP BYclause in SQL is used to arrange identical data into group with the help of aggregate functions (e.g.,SUM()).
A View Under-the-hood 🔎
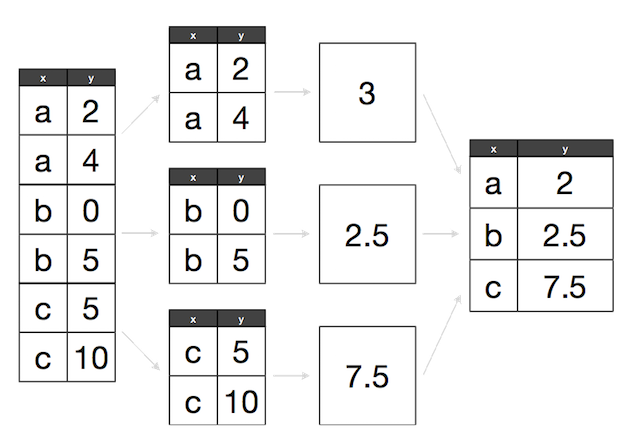
So what is happening under-the-hood? Split-apply-combine.
GROUP BYsplits data into groups based on criteria.- A function (e.g.,
SUM) is applied to each group independently. - Group results are combined into a data structure.
⚡ Challenge
Write a single or multiple query(ies) that return(s):
- The total prison population for California per year
- The average prison population in each county in California per year (bonus points if you can round this value to two significant figures)
- How many county observations were included in the aggregation per group
You got time ⏱️, but not too much.
Aliases 🏷️
As your queries get more complex, and your calculations more verbose, the returned variable names will likely get long and unwieldy. To help make things clearer, we can use aliases to assign new names to returned values in the queries.
To do so, use AS:
Tip
Technically, AS isn’t required. So you could do:
SELECT State, Year,
SUM(Prison_Population_Total) Yearly_Prison_Population_Sum,
ROUND(AVG(Prison_Population_Total), 2) Yearly_Prison_Population_Avg,
FROM [Vera - Prison Numbers by State-County - 1990 to current]
WHERE State == "California"
GROUP BY Year, State;However, I ask that you include it to improve clarity.
🤏 HAVING isn’t WHERE
Previously, we discussed WHERE, which allows you to filter the results of a query based on some criteria.
SQL offers another tool for filtering data based on aggregate functions, through the HAVING keyword. For example, suppose that you only want to return observations generated with inputs for all 58 counties in California:
SELECT State, Year,
SUM(Prison_Population_Total) AS Yearly_Prison_Population_Sum,
ROUND(AVG(Prison_Population_Total), 2) AS Yearly_Prison_Population_Avg,
COUNT(Prison_Population_Total) AS Yearly_State_County_N
FROM [Vera - Prison Numbers by State-County - 1990 to current]
WHERE State == "California"
GROUP BY Year, State
HAVING Yearly_State_County_N = 58;Challenge⚡
Write a query that returns observations for the CA yearly prison population, where that yearly number is below 100,000 and that number was generated from observations from all 58 counties.
You got time ⏱️, but not too much.
My answer is:
SELECT State, Year,
SUM(Prison_Population_Total) AS Yearly_State_Population_Sum,
-- ROUND(AVG(Prison_Population_Total), 2) AS Yearly_State_Population_Avg,
COUNT(Prison_Population_Total) AS Yearly_State_County_N
FROM [Vera - Prison Numbers by State-County - 1990 to current]
WHERE State == "California"
GROUP BY Year, State
HAVING Yearly_State_Population_Sum < 100000 AND
Yearly_State_County_N = 58;What is yours?
⛩️ The Sacred Art of DRY
Now that you are an SQL ninja 🥷, it’s time that we tackle how to handle repetitive operations.
“With great power comes great responsibility” – Ben Parker
Your new goal is to live by the DRY principle, or “Don’t Repeat Yourself”. This principle is foundation in software development but can be useful in building queries in SQL. The idea here is to reduce the repetition of code patterns and ensuring maintainability (code is in less places), readability (more compact code), and reusability (modular data).
One way to minimize repetition is by creating and using views. Views are are a form of query that can be saved in the database, and can be used at a later time, filtered, or even updated.
Saving Queries for Future Use with Views 💾
Suppose that your project requires reporting on California periodically. That query would look like:
SELECT *
FROM [Vera - Prison Numbers by State-County - 1990 to current]
WHERE State == "California",But if we don’t want to type that every time (think DRY 🥷), you can create a view:
That is a wrap folks! 🎉
🔑 Key Take Aways
- Use the
GROUP BYkeyword to aggregate data. - Functions like
MIN,MAX,AVG,SUM,COUNT, etc. operate on aggregated data. - Aliases can help shorten long queries. To write clear and readable queries, use the
ASkeyword when creating aliases. - Use the
HAVINGkeyword to filter on aggregate properties. - Use a
VIEWto access the result of a query as though it was a new table.
❓Questions?

Resources 🔗
- w3school’s SQL tutorial
- codecademy’s SQL tutorial
- Data Management with SQL for Social Scientists
- SQL Basics Cheat Sheet
- Google (e.g., “how do i … in SQL with …”)
Credits 🙏
This presentation was largely adapted from the wonderful course “Data Management with SQL for Ecologist” by datacarpentry.org and Cathy Tanimura’s “SQL for Data Analysis” book.
![]()
For Internal Use Only