9 Subgrupos Cohesivos
En este capítulo, exploraremos algunos (pero no todos) métodos para hallar subgrupos cohesivos de actores dentro de una red social. Los subgrupos cohesivos son subconjuntos de actores entre los cuales existen fuertes lazos, por ello los métodos que utilizaremos formalizan la existencia de un grupo social a través de características estructurales de una red (Wasserman & Faust, 1994).
En esta breve introducción cubriremos: componentes, núcleos (k-core), grupos Girvan-Newman y de Louvain. Para poner este nuevo conocimiento en práctica, el capítulo concluye con un ejercicio práctico de como implementar estas medidas en Gephi.
9.1 Componentes
Estos son la forma más simple de subgrupos cohesivos en ARSo. Representan subredes en las cuales los miembros están conectados los unos a los otros (directa o indirectamente) pero no a miembros de otras subredes (Everton, 2012a, p. 171). Los componentes pueden ser divididos en dos campos, fuertes o débiles.
9.1.1 Componentes Débiles
Los nodos en un grafo desconectado se pueden dividir en dos o más subconjuntos de manera que no haya caminos entre los nodos en diferentes conjuntos (Wasserman & Faust, 1994), estos subconjuntos del grafo se llaman componentes débiles. Localizar componentes débiles es apropiado para datos dirigidos o no dirigidos, puesto que el objetivo es localizar subconjuntos conectados. Tome por ejemplo la Figura 9.1. En esta imagen, el color de los nodos denota el componente débil al que pertenecen. Como puede observar, encontramos tres componentes débiles en dicho gráfico, uno con cinco actores, una diada, y un aislado.
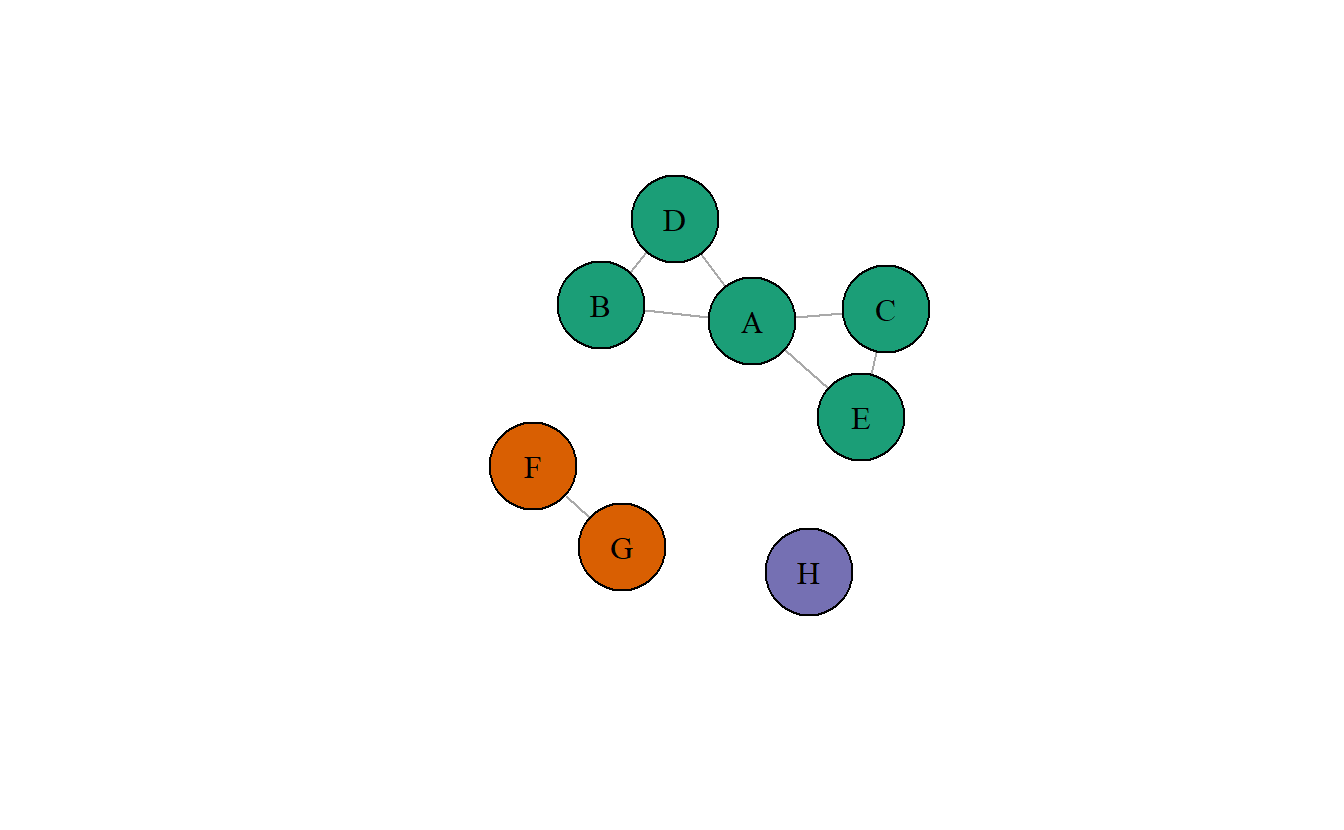
Figura 9.1: Red con múltiples componentes débiles
El detectar componentes débiles no solo sirve para colorear los grafos, de hecho, una de las aplicaciones más comunes es el aislar componentes. Por ejemplo, la densidad del grafo en la Figura 9.1 es 0.25. Este índice sugiere una red escarza, sin embargo, de manera visual podemos ver que algunos componentes son más densos que otros. El componente principal, aquel de mayor tamaño, aparenta ser más denso. Es por ello que podemos aislar este componente principal y al ejecutar la medida de densidad nuevamente vemos un valor de 0.6. Este proceso nos permite enfocarnos en diferentes subconjuntos del grafo en nuestro análisis.
9.1.2 Componentes Fuertes
Este tipo de subgrupo solo es adecuado cuando los datos son dirigidos. Easley & Kleinberg (2010) definen los componentes fuertes en un grafo dirigido como subconjuntos de nodos en los cuales (A) que todos los nodos en el subconjunto pueden alcanzarse entre sí y (B) el subconjunto no es parte de un conjunto mayor con la propiedad que los nodos pueden llegar a todos los demás. Por ejemplo, en la Figura 9.2 el color de los nodos denota membresía a un subcomponente fuerte.
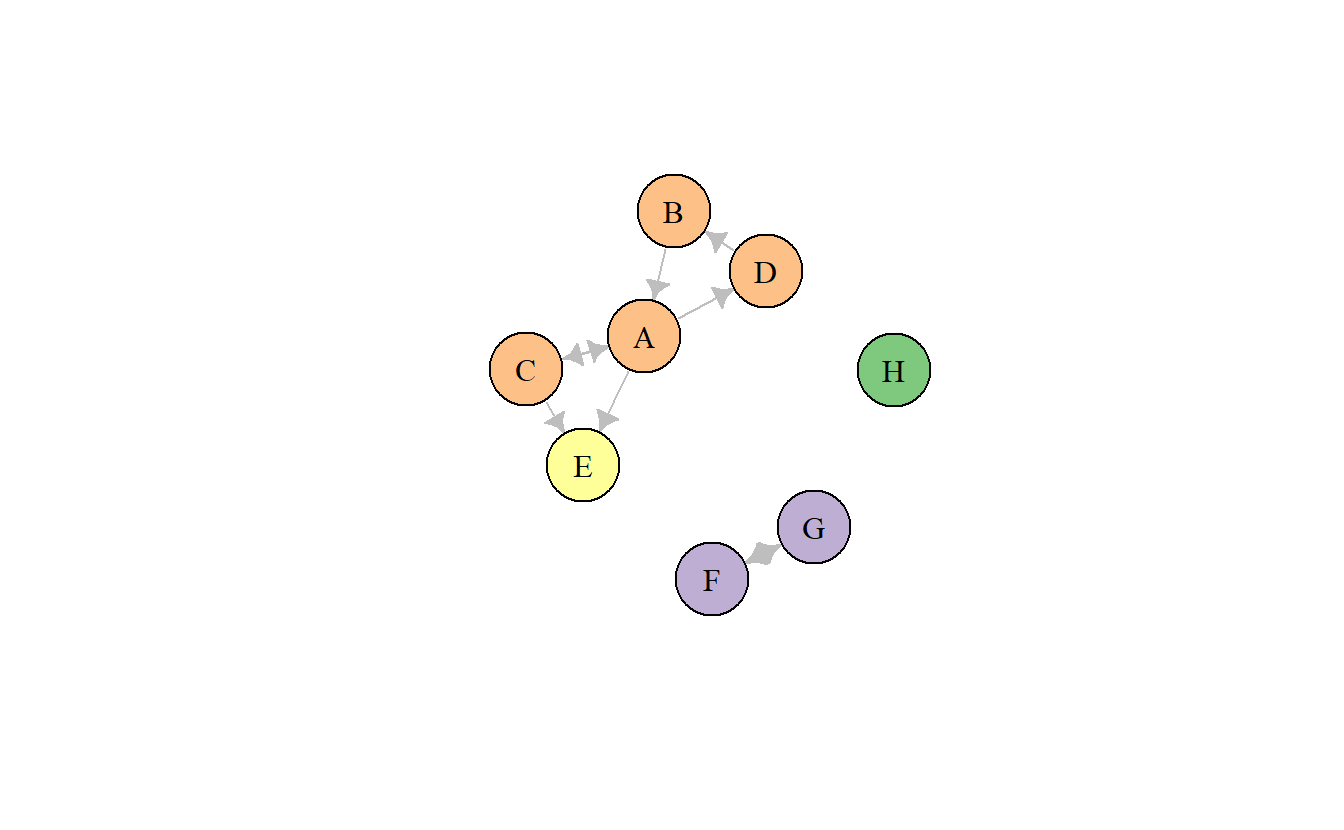
Figura 9.2: Red con múltiples componentes fuertes
Observe que en esta ocasión encontramos cuatro componentes fuertes, el primero se encuentra compuesto por un actor aislado {H}, el segundo es una diada reciproca {F, G}, el tercero es un solo actor {E}, y el cuarto sería el componente fuerte principal {A, B, C, D}. Es probable que se esté preguntando, ¿Por qué E no forma parte del componente fuerte principal? La razón la podemos encontrar en la definición de Easley y Kleinberg. Note que en el componente principal todos los nodos pueden alcanzarse entre sí, es decir, si cualquier nodo en el componente fuese a difundir alguna noticia a través de sus contactos esta información podría retornar al originador. Sin embargo, E se encuentra en un componente único puesto que no alcanza a otros nodos.
Como puede ver, los componentes fuertes son más restrictivos que los componentes débiles. Sin embargo, son útiles al trabajar con datos dirigidos puesto que permiten el análisis de subconjuntos donde todos los nodos pueden alcanzarse entre sí tomando en cuenta la direccionalidad de vínculos dirigidos y el flujo potencial de información y/o recursos.
9.2 K-cores
Otra forma de localizar subgrupos cohesivos en una red es basándose en grados nodales; específicamente, utilizando k-cores (o k-núcleos) que se definen en términos del grado mínimo. Donde k, en un subgrafo es el número mínimo de nodos adyacentes (Wasserman & Faust, 1994) . Por ejemplo, el primer grafo (red completa) en la Figura 9.3 representa un grafo completo, es decir, 0-core. En este, vemos nodos aislados con cero enlaces, nodos pendientes con un solo vínculo y nodos con una variedad de grados de centralidad. Un 1-core incluye todos los nodos conectados al menos a una persona (ver Figura 9.3). Similarmente, un 2-core incluye nodos conectados al menos a dos otros nodos (ver Figura 9.3). De igual manera podemos definir un 3-core como nodos con tres o más vínculos (ver Figura 9.3). Al aumentar k comenzamos a localizar el núcleo de actores más interconectados de la red, de igual manera el subconjunto restante aumentará en densidad (Valente, 2010).
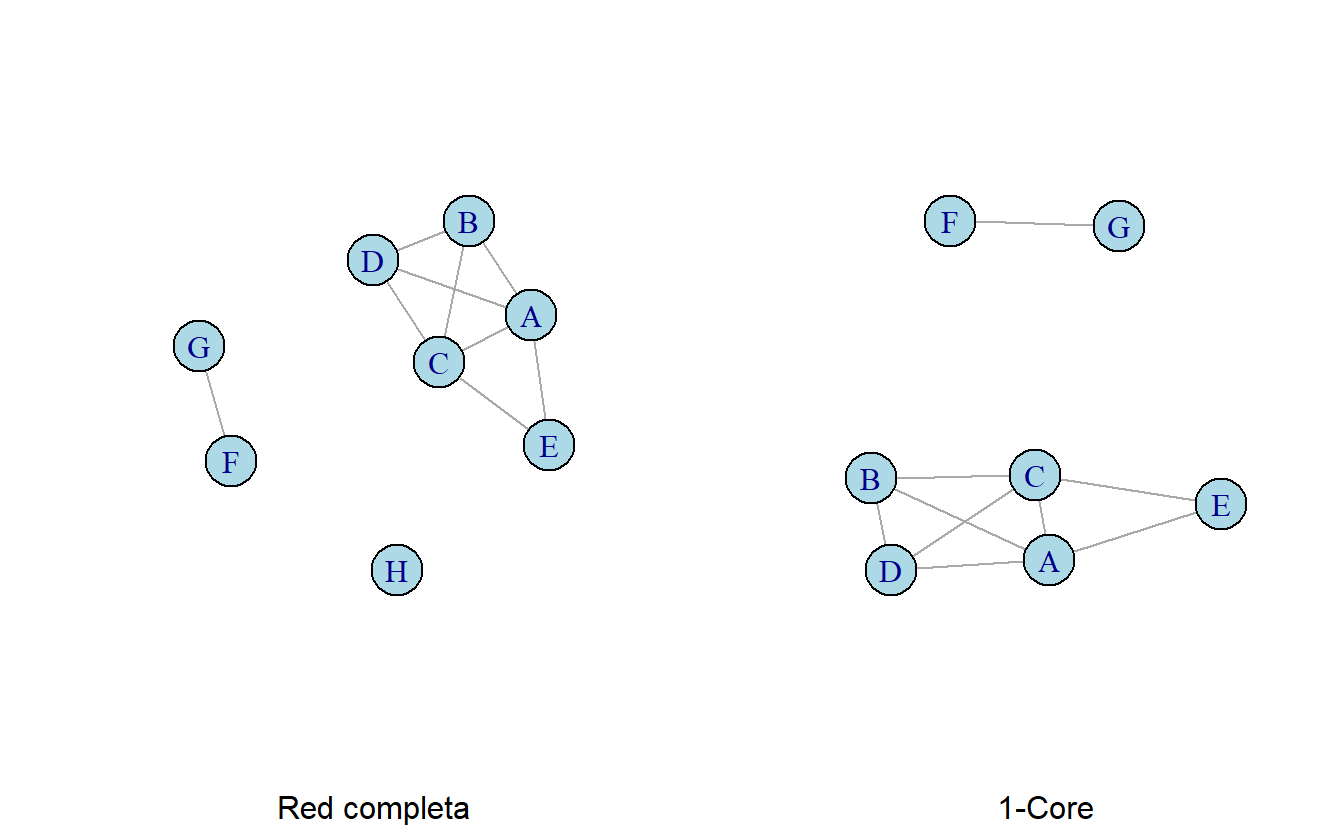
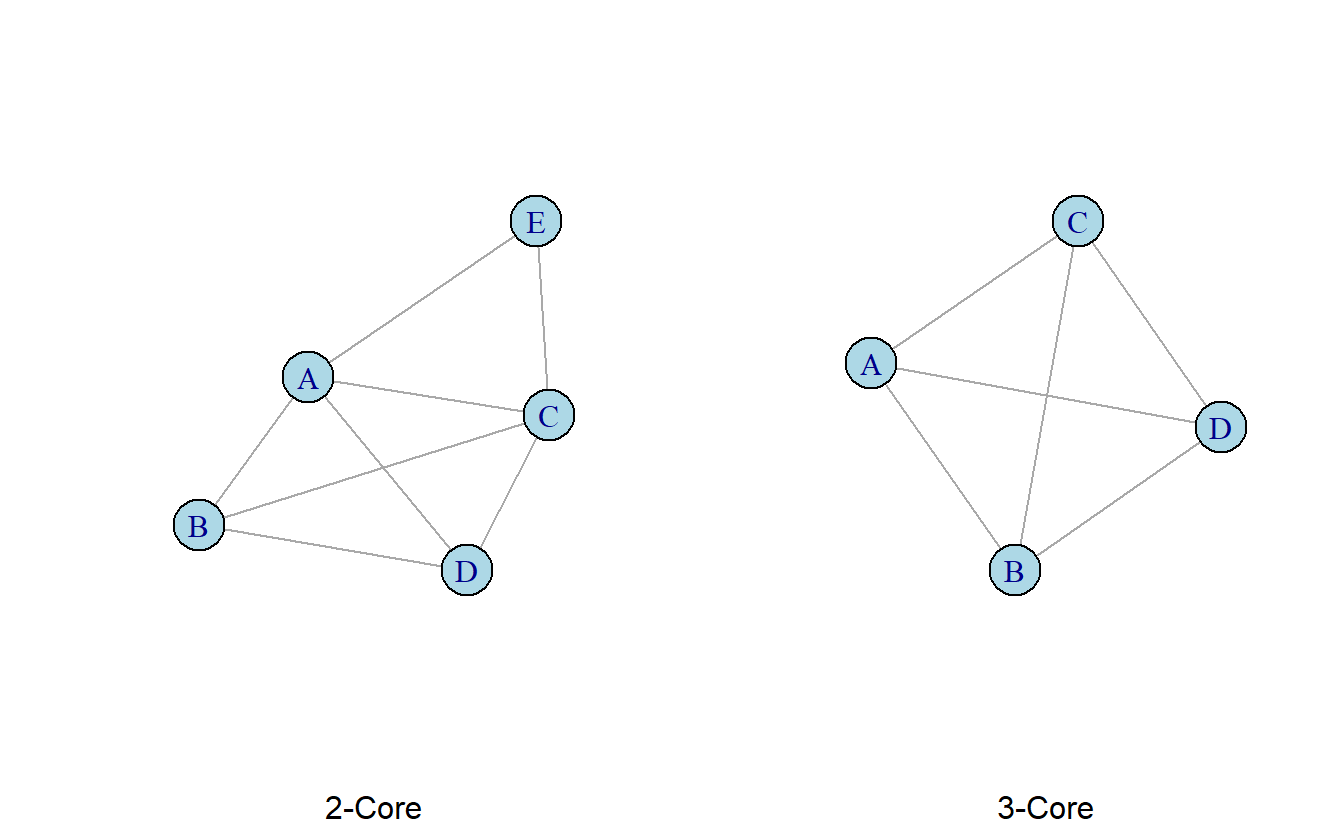
Figura 9.3: Red completa y 1-, 2-, y 3-core
El remover nodos incrementando k es una estrategia comúnmente utilizada por analistas de redes para describir la estructura de la red. Específicamente, para aislar el núcleo de la periferia, o los actores más activos de los actores con pocas conexiones.
9.3 Girvan-Newman
El algoritmo de Girvan y Newman (2004) detecta subcomunidades enfocándose en remover vínculos intermediarios entre subconjuntos de nodos con el propósito de localizar subcomponentes. Por ejemplo, en la red 9.4 (izquierda) vemos dos tríadas cerradas conectadas a través de un puente. En este gráfico los vínculos han sido dibujados de manera ponderada con base en la intermediación de cada enlace. El algoritmo de Girvan y Newman comienza por calcular la intermediación de los enlaces, remueve de manera sistemática aquellos con el mayor índice de intermediación y procede a recalcularla y remover enlaces con alto valor de manera iterativa. Supongamos que ejecutamos este algoritmo por un ciclo, entonces al remover el puente entre tríadas se produce dos subconjuntos, mejor descritos como componentes débiles (ver, derecha).
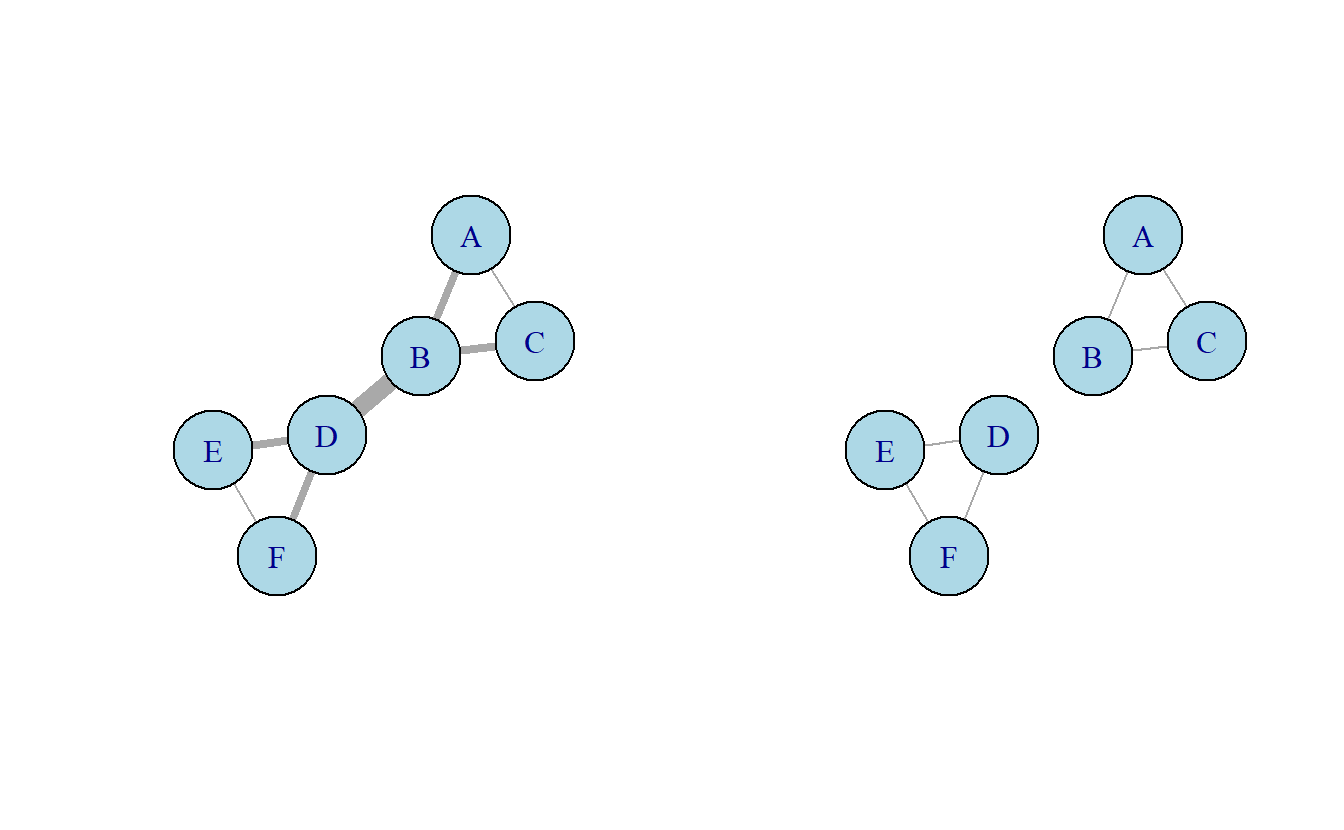
Figura 9.4: Red hipotética (izquierda) y componentes débiles (derecha)
En práctica, el algoritmo ejecuta este proceso y retorna un valor categórico correspondiente a la subcomunidad a la que pertenece cada nodo. Por lo tanto, el gráfico original no se ve afectado y el analista gana información sobre la comunidad Girvan-Newman correspondiente para cada nodo. Por ejemplo, la Figura 9.5 contiene la red previa con comunidades Girvan-Newman resaltadas.
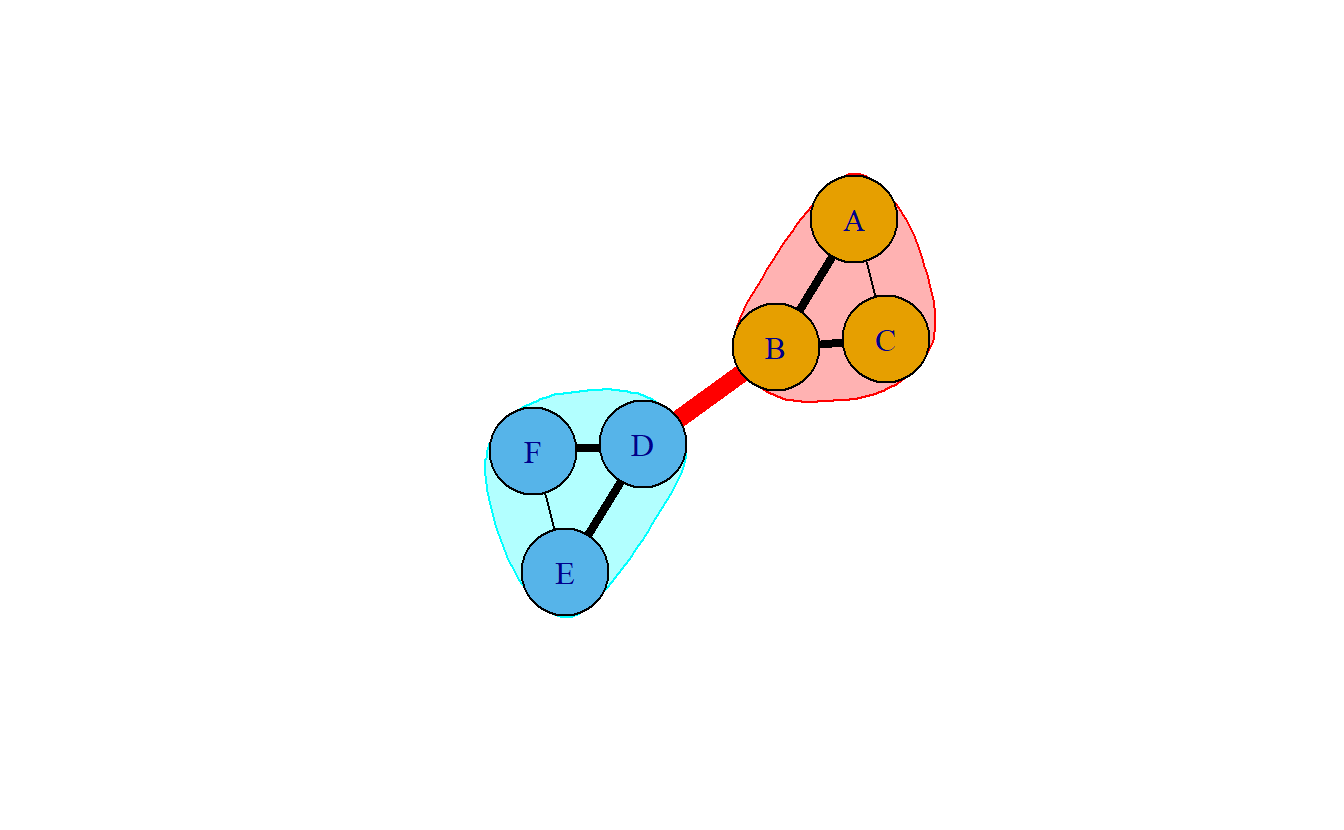
Figura 9.5: Comunidades Girvan-Newman y puentes resaltados.
El algoritmo de Girvan-Newman provee una forma de generar particiones de la red a grupos mutuamente exclusivos y un índice que mide la adecuación de estas particiones, de tal forma que el analista puede elegir entre estas particiones en busca de la más adecuada conforme a los datos de la red (Valente, 2010, p. 106). Normalmente, la partición de la red que genera el índice de modularidad más alto es considerado el punto óptimo (Everton, 2012a).
9.3.1 Modularidad
La modularidad mide la fuerza de la división de una red en módulos (a veces llamados particiones, comunidades, etc.). En términos prácticos, las redes con alta modularidad tienen conexiones densas dentro de los módulos pero escasa entre estos. Se define como:
\[ Q = \frac{1}{2m} \sum_{i, j}[A_{ij} – \frac{k_{i}k_{j}}{2m}]\delta(c_i, c_j) \]
Donde \(A_{ij}\) es el peso del vínculo entre los nodos \(i\) y \(j\). \(k_{i}\) y \(k_{j}\) son los grados de cada nodo correspondiente. \(\delta(c_i, c_j)\) o la delta Kronecker tiene un valor de 1.0 si ambos \(i\) y \(j\) corresponden a la misma partición, de otra manera el valor es 0.0. Por último, \(m\) corresponde al número de vínculos en la red.
El siguiente es un ejemplo de cómo calcular la modularidad de una red a mano con base en el ejemplo de Matthew Joseph en ResearchGate y luego Abhishek Mishra. Empecemos con nuestra pequeña red 9.6 y su matriz de adyacencia.
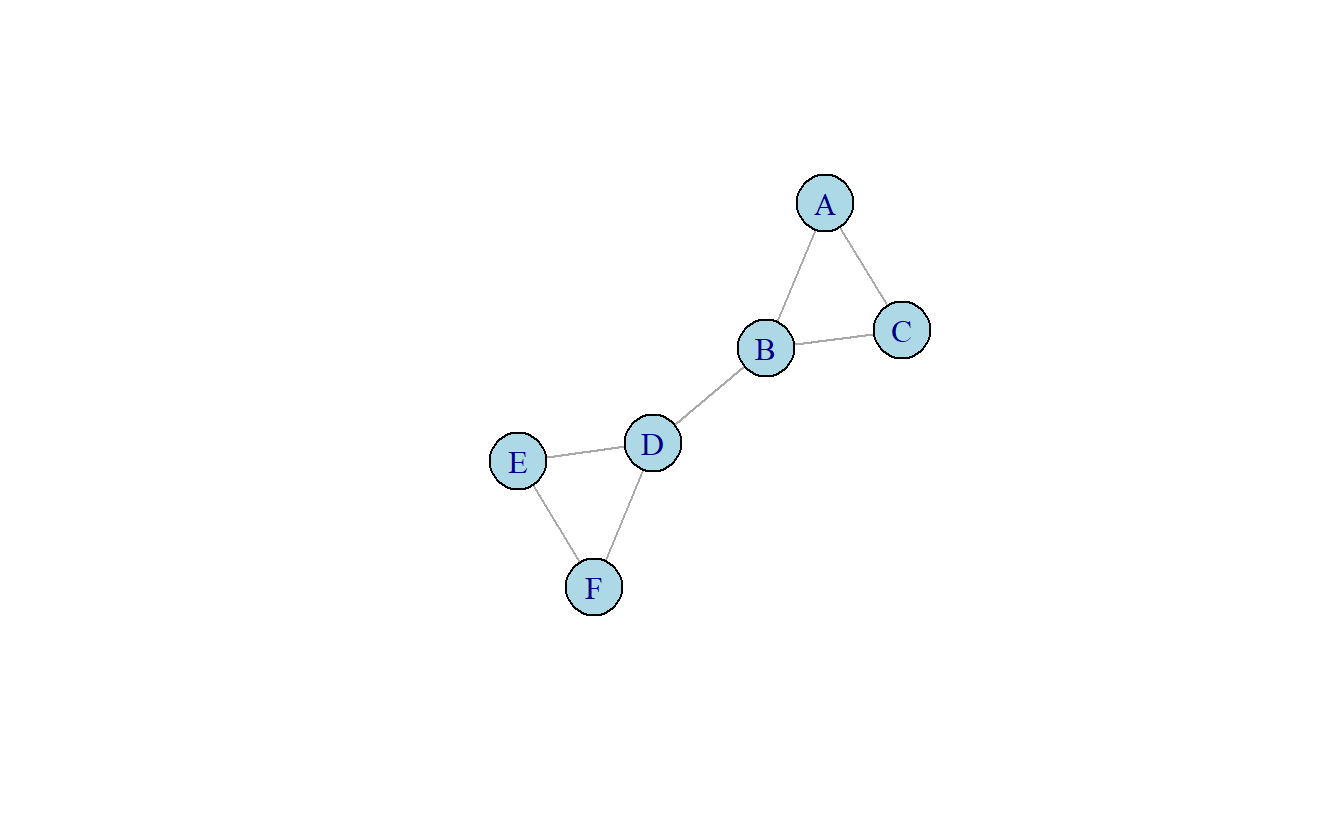
Figura 9.6: Red hipotética
\[ \begin{matrix} & A & B & C & D & E & F \\ A & - & 1 & 1 & 0 & 0 & 0 \\ B & 1 & - & 1 & 1 & 0 & 0 \\ C & 1 & 1 & - & 0 & 0 & 0 \\ D & 0 & 1 & 0 & - & 1 & 1 \\ E & 0 & 0 & 0 & 1 & - & 1 \\ F & 0 & 0 & 0 & 1 & 1 & - \\ \tag{9.1} \end{matrix} \]
La implementación del algoritmo Girvan-Newman comienza por remover el vínculo con la mayor intermediación, en este caso el puente entre los actores D y B. Aquí utilizaremos esta partición como punto de inicio, es decir, la primera partición contiene los nodos {A, B, C} y la segunda {D, E, F}. Igualmente, el número de enlaces en este grafo es \(m\) = 7 y el grado de cada nodo es equivalente a:
\[ \begin{matrix} & Grado \\ A & 2 \\ B & 3 \\ C & 2 \\ D & 3 \\ E & 2 \\ F & 2 \\ \tag{9.2} \end{matrix} \]
Con esta información disponible, podemos calcular la modularidad del grafo:
\[ \small \begin{aligned} Q = \frac{1}{2 \times 7} (\\ &\text{A a A: no conectados (0), mismo grupo (1)}\\ &(0 - \frac{2 \times 2}{(2 \times 7)}) \times 1 + && \\ &\text{A a B: conectados (1), mismo grupo (1)} \\ &(1 - \frac{2 \times 3}{(2 \times 7)}) \times 1 + && \\ &\text{A a C: conectados (1), mismo grupo (1)} \\ &(1 - \frac{2 \times 2}{(2 \times 7)}) \times 1 + && \\ &\text{A a D: no conectados (0), otro grupo (0)} \\ &(0 - \frac{2 \times 3}{(2 \times 7)}) \times 0 + && \\ &\text{A a E: no conectados (0), otro grupo (0)} \\ &(0 - \frac{2 \times 2}{(2 \times 7)}) \times 0 + && \\ &\text{A a F: no conectados (0), otro grupo (0)} \\ &(0 - \frac{2 \times 2}{(2 \times 7)}) \times 0 + && \\ &\text{B a B: no conectados (0), mismo grupo (1)} \\ &(0 - \frac{3 \times 2}{(2 \times 7)}) \times 1 + && \\ &\text{B a A: conectados (1), mismo grupo (1)} \\ &(1 - \frac{3 \times 2}{(2 \times 7)}) \times 1 + && \\ &\text{B a C: conectados (1), mismo grupo (1)} \\ &(1 - \frac{3 \times 2}{(2 \times 7)}) \times 1 + && \\ &\text{B a D: conectados (1), otro grupo (0)} \\ &(1 - \frac{3 \times 3}{(2 \times 7)}) \times 0 + && \\ &\text{B a E: no conectados (0), otro grupo (0)} \\ &(0 - \frac{3 \times 2}{(2 \times 7)}) \times 0 + && \\ &\text{B a F: no conectados (0), otro grupo (0)} \\ &(0 - \frac{3 \times 2}{(2 \times 7)}) \times 0 + && \\ &...)\\ \end{aligned} \]
Podemos simplificar la operación previa como:
\[ Q = \frac{1}{2 \times 7} (4(1) + 2(0.5)) = 0.3571 \]
La modularidad con los nodos {A,B,C} y {D, E, F} en particiones separadas es igual a \(Q\) = 0.3571. En este ejemplo no continuaremos removiendo enlaces y asignando nuevas particiones, como lo haría el algoritmo Girvan-Newman. El objetivo de este ejercicio breve es presentarle en mayor detalle el mecanismo utilizado para calcular la modularidad de una red y determinar el número óptimo de subcomunidades.
9.4 Louvain
Publicado originalmente en 2008, el método Louvain es un método de optimización codicioso que intenta optimizar la modularidad de las particiones de la red. Esencialmente, la optimización se lleva a cabo en dos pasos. Primero, el método encuentra pequeñas comunidades locales optimizando la modularidad. Luego, agrega nodos que pertenecen a las comunidades identificadas y construye una nueva red con esos nodos colapsados. El proceso continúa hasta que se identifique la máxima modularidad y se produzca una jerarquía de comunidades (Blondel, Guillaume, Lambiotte, & Lefebvre, 2008).
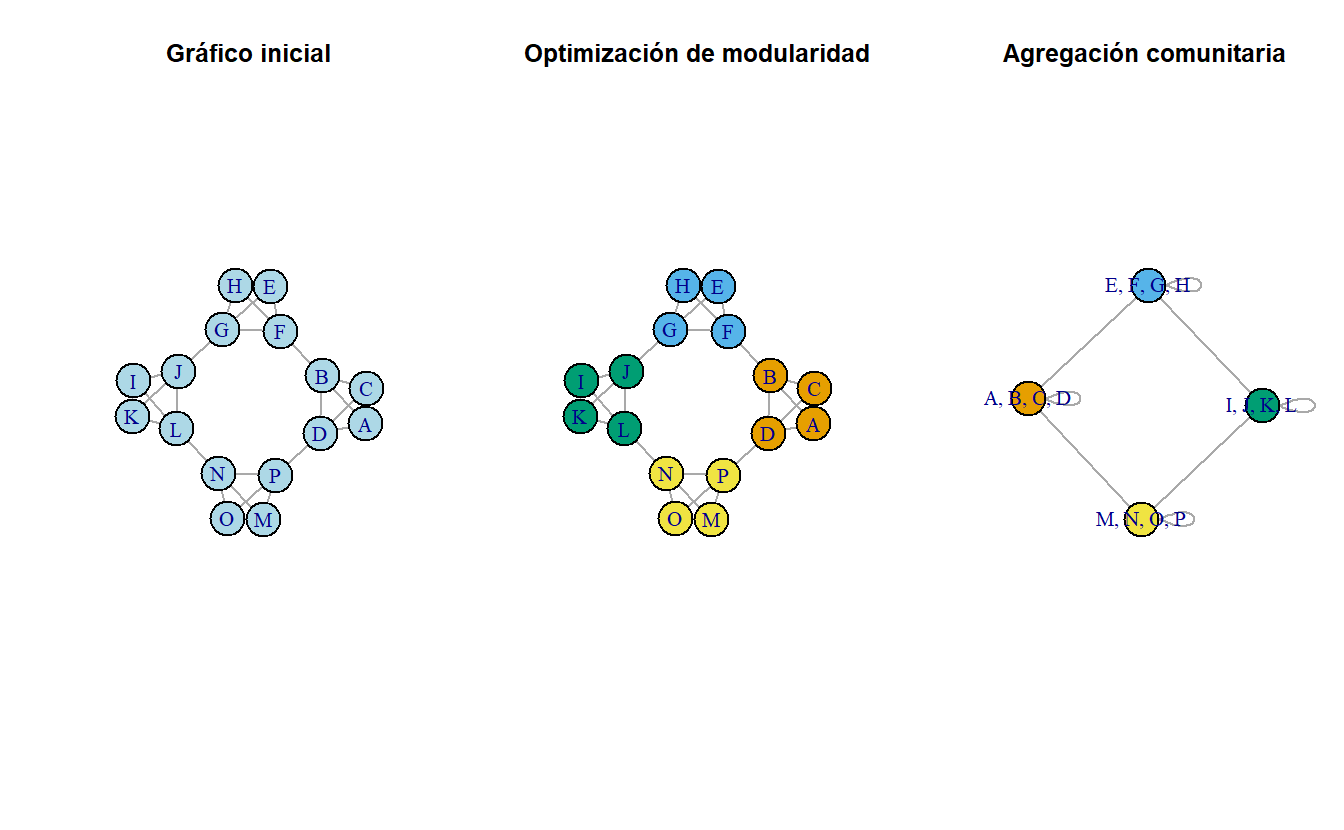
Figura 9.7: Visualización de los pasos en el algoritmo
La Figura 9.7 es una representación gráfica de una sola ronda en el proceso. Sin embargo, en términos prácticos, el proceso resulta en particiones que denotan las subcomunidades a las que pertenece cada nodo. La red izquierda de la Figura 9.8 consta de 100 nodos, a su derecha vemos las subcomunidades óptimas detectadas por el algoritmo de Louvain. Es importante recalcar que el objetivo del algoritmo es optimizar la modularidad y por consiguiente los grupos resultantes son una representación matemática de los patrones de enlaces en el gráfico. Sin embargo, este tipo de herramienta analítica es útil en localizar comunidades cohesivas donde los miembros tienen normas, valores o aptitudes similares. Otra manera de pensar en esto es que los nodos dentro de cada grupo pueden seleccionarse a sí mismos como parte del grupo o las presiones sociales del grupo pueden persuadir a los nuevos miembros para que adopten normas o valores del grupo (Valente, 2010, p. 108).

Figura 9.8: Red sin escala (izquierda) y red sin escala con particiones (derecha)
9.5 Ejercicio Práctico
Los científicos sociales generalmente asumen que la interacción social es la base de la solidaridad, las normas compartidas, la identidad y el comportamiento colectivo, por lo que es probable que las personas que interactúan intensamente se consideren parte de un grupo social. Por lo tanto, una herramienta principal del análisis de redes sociales es identificar grupos densos de actores entre los cuales hay vínculos relativamente fuertes, directos, intensos y / o positivos. Por lo general, se denominan “subgrupos cohesivos,” “subredes” o “subgrupos.” Una forma de agrupar a los actores se basa en atributos compartidos (por ejemplo, raza, género, etc.). Otro es utilizar el patrón de vínculos entre actores.
En un mundo ideal, habría un solo algoritmo para identificar subgrupos cohesivos, pero este no es un mundo ideal, por lo que los analistas de redes sociales han desarrollado una variedad de algoritmos para identificar subredes. No los consideraremos todos aquí; simplemente hay demasiados. En cambio, nos centraremos en algunos. En Gephi consideraremos componentes, k-cores y algoritmos de detección de comunidades.
9.5.1 Antes de Empezar
Para este ejercicio vamos a necesitar el módulo Newman-Girvan clustering antes de comenzar Haga esto siguiendo los mismos pasos que utilizamos en para descargar el módulo MultimodeNetworks Transformation en ejercicio práctico en el capítulo Derivando Datos Modo-Uno de Modo-Dos.
9.5.2 Identificación de Subgrupos en Gephi
Archivo > Abrir
- Abra Gephi y lea el archivo
alive_trust_network.gephi, que puede descargar aquí. Comenzaremos explorando componentes, estos son subgrupos de actores que están conectados (ya sea directa o indirectamente) entre sí. En las redes dirigidas, puede identificar dos tipos de componentes: fuertes y débiles. Los componentes fuertes toman en cuenta la dirección de los lazos, mientras que los componentes débiles no. Con redes no dirigidas, solo puede identificar componentes débiles.
Estadísticas > Componentes conexos > Ejecutar
- Para identificar componentes en Gephi, haga clic en Ejecutar junto a la función Componentes conexos en la pestaña Estadísticas. Aparecerá un cuadro de diálogo titulado Parámetros de Componentes Conectados (no se muestra) que ofrece la opción de indicar si nuestros datos son Dirigidos o No dirigidos. Aquí, estamos trabajando con datos no dirigidos, así que elija esta opción y haga clic en Aceptar. Ahora deberá aparecer el informe Connected Componenets Report (Reporte de Componentes conectados) (Figura 9.9), que reporta los parámetros de la red, el número de componentes Results (Resultados) y un gráfico que indica el número y tamaño de cada uno de los componentes. Como puede ver, Gephi encontró 8 componentes, pero al comparar esta cifra con el gráfico de red, podemos ver que 7 de estos son nodos aislados. Igualmente podemos llegar a esta conclusión examinando el gráfico en el informe. Si observa verá que hay 7 componentes de tamaño 1 y un componente un poco más grande que 60 (62 en realidad). Cierre la ventana del informe cuando haya terminado.

Figura 9.9: Reporte de Componentes Conectados en Gephi
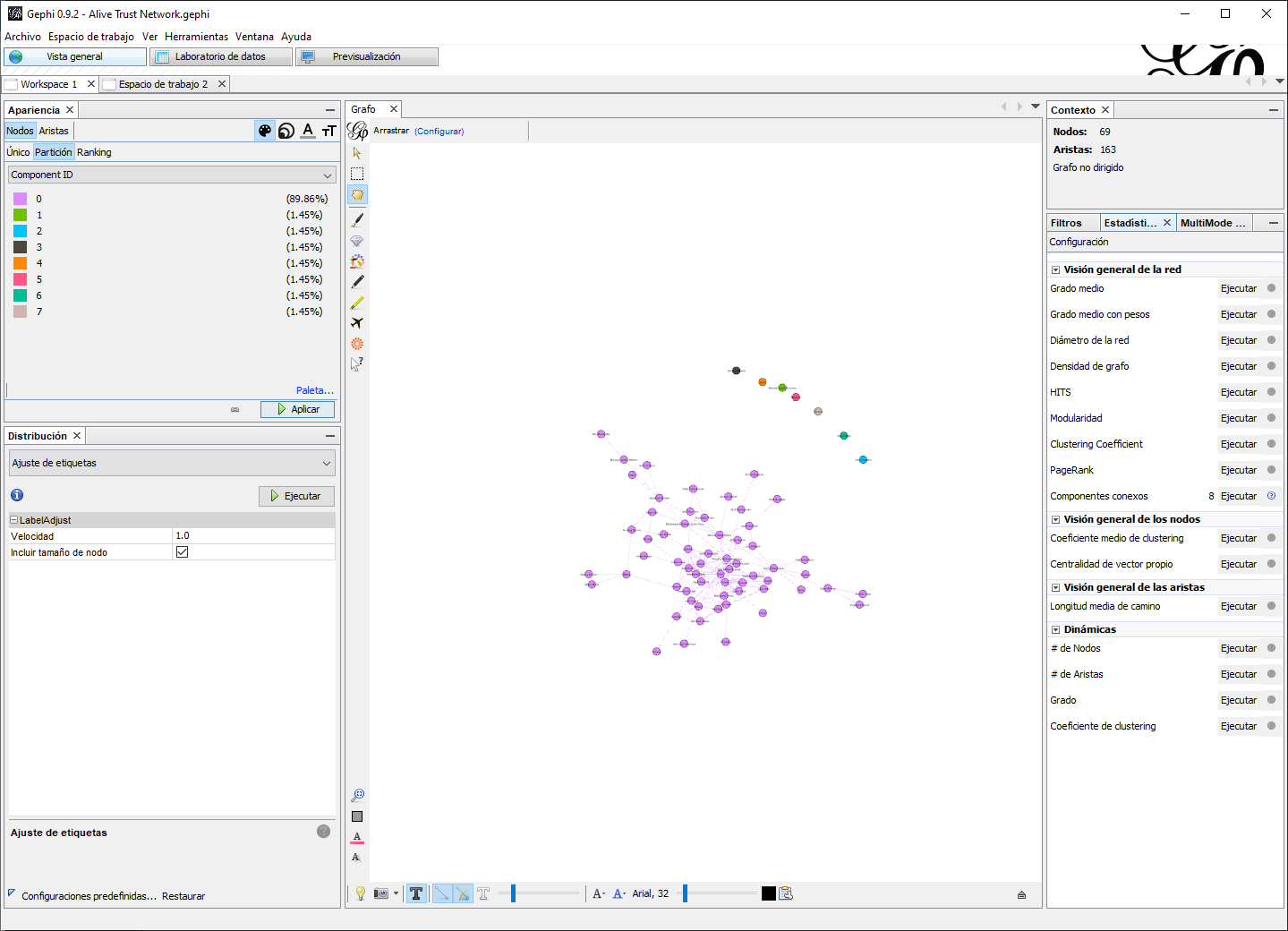
Figura 9.10: Red de confianza con actores vivos, color por componente
Tabla de datos > Nodos
Apariencia > Nodos > Color > Partición > –Escoge un atributo > Component ID > Aplicar
- También puede ver los resultados navegando al Laboratorio de datos y buscando una nueva columna (partición) en la sección Nodos denominada Component ID (identificación del componente). Gephi genera una serie de números, comenzando con 0, que identifican los componentes respectivos de cada actor. También podemos usar esta variable categórica para visualizar la red, seleccionando primero la opción Nodos> Color> Partición en la pestaña Apariencia, y luego con el menú desplegable –Escoge un atributo, seleccione Component ID y de clic en Aplicar. El resultado no es muy interesante (Figura 9.10) ya que cada nodo aislado posee un color diferente, mientras que los actores conectados en el componente más grande (llamado componente principal) son todos del mismo color.
Filtros > Atributos > Partición > Consultas > Filtrar > Exportar el grafo filtrado en un nuevo espacio de trabajo
- No obstante, puede que en algunas ocasiones sea útil identificar el componente principal. De hecho, no es raro que los investigadores extraigan el componente principal y lo analicen por separado. Por lo tanto, exportaremos el componente principal a un espacio de trabajo separado donde lo analizaremos. Para hacer esto, en la pestaña Filtros a la derecha de la ventana Vista general, primero seleccione Atributos y luego Partición. A continuación, arrastre la partición Component ID a Consultas. En las opciones abajo, haga clic en el cuadro que tiene el mayor porcentaje de nodos (probablemente
0), seleccione Filtrar y luego use el botón Exportar el grafo filtrado en un nuevo espacio de trabajo (Figura 9.11). ¿Cuál es el tamaño del componente principal? ¿Cuál es su densidad? ¿Grado medio?
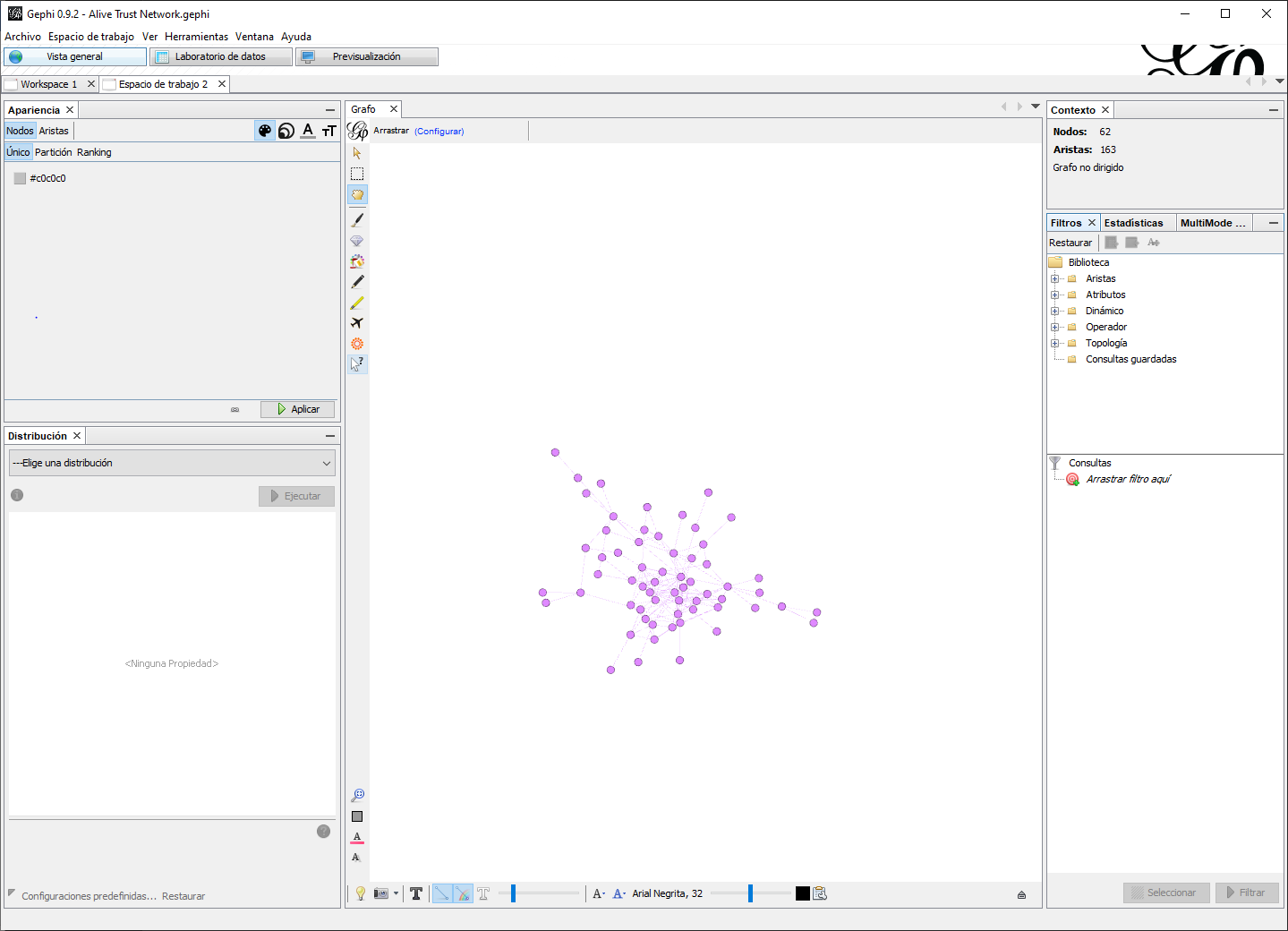
Figura 9.11: Red de confianza con actores vivos, componente principal
- Veamos si identificar k-cores es una mejor estrategia para identificar subgrupos cohesivos para esta red en particular. La “k” en k-core indica el número mínimo de vínculos de cada actor dentro del núcleo (“core”); por ejemplo, un núcleo 2 incluye a todos los actores que tienen dos o más conexiones con otros actores dentro del núcleo, y un núcleo 3 incluye todos los actores que tienen tres o más vínculos con otros actores dentro de un núcleo. Es importante tener en cuenta que el k-core más alto de una red no corresponde necesariamente al puntaje de centralidad de grado más alto obtenido por un actor en la red. Más bien, es el subgrupo en el que cada actor comparte el mayor número de vínculos. Imagínese una red en la que un actor tiene seis vínculos, pero nadie más tiene más de cuatro. El k-core más alto no sería un 6-core porque todos los demás en el subgrupo también necesitarían tener seis enlaces.
Filtros > Topología > K-core
- Regrese a la pestaña Alive Trust Network. Una vez más usaremos un filtro para encontrar k-cores. Esta vez, arrastre la opción K-core que se encuentra en la sección de Topología en la pestaña Filtro a Consultas. Hacia la parte inferior de la pestaña Filtros, deberá ver un cuadro K-core Configuración que estará predeterminado en 1. Haga clic en el botón Filtrar y los aislados deberán desaparecer. Aumente la configuración a 2 y no debería haber ningún cambio. Eso es porque Gephi aparentemente cuenta los lazos dos veces, para reflejar las dos direcciones de un enlace aunque, en este caso, Gephi sabe (o debería saber) que se trata de una red no dirigida. Por lo tanto, el filtro de 1 y 2 capturan el primer núcleo (k = 1), 3 y 4 capturan el segundo núcleo (k =2), y así sucesivamente. Si sigue aumentando la configuración, todos los nodos desaparecen al llegar a quince, lo que significa que el núcleo k más alto de la red es el séptimo núcleo (14/2). Vea la Figura 9.12. Exporte el 7-core a un nuevo espacio de trabajo. ¿Qué actores parecen ser los más centrales en la red del séptimo núcleo (k = 7)?
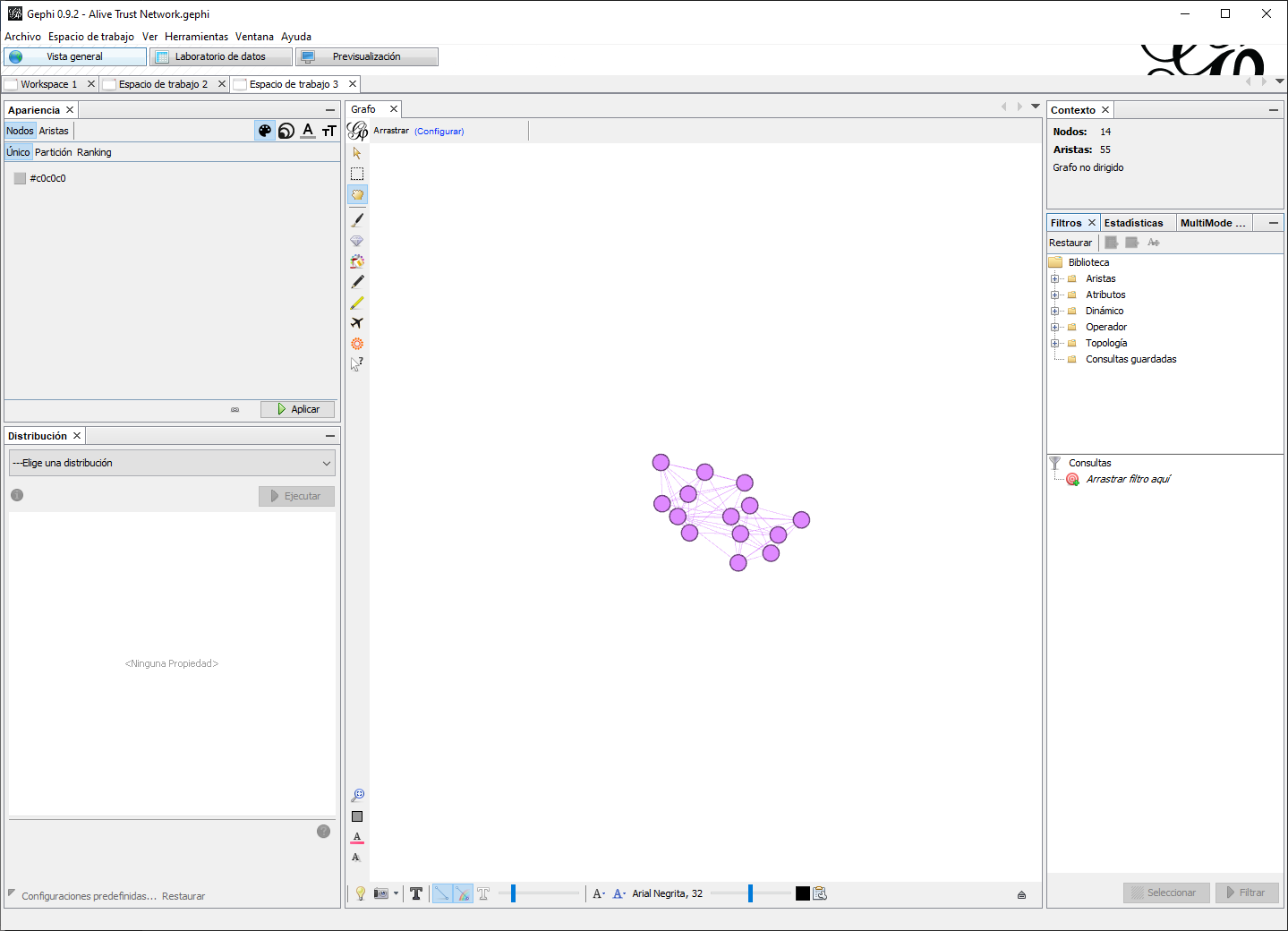
Figura 9.12: Red de confianza con actores vivos, 7-core
Estadísticas > Girvan-Newman Clustering > Ejecutar
- Ahora consideremos otro método para identificar subgrupos: algoritmos de detección de comunidades. Consideraremos dos: Girvan-Newman y Louvain. El segundo estará implementado automáticamente en Gephi, pero Girvan-Newman no, por lo que deberá descargar e instalar el módulo Newman-Girvan Clustering, si aún no lo ha hecho. En la pestaña Estadísticas de Alive Trust Network, haga clic en el botón Ejecutar a un lado de función Girvan-Newman Clustering. Esto abrirá un cuadro de diálogo (no se muestra). Acepte los valores predeterminados y haga clic en Aceptar. Esto producirá un informe (no se muestra) que indica el número de comunidades que detectó y la modularidad. ¿Cuántas comunidades encontró el algoritmo?
Apariencia > Nodos > Color > Partición > –Escoge un atributo > Cluster-ID > Aplicar
- Asimismo, coloree los nodos según la partición creada por el algoritmo (Cluster-ID). Note que el algoritmo Girvan-Newman ha asignado cada uno de los aislados a una comunidad separada. No todos los algoritmos de detección de comunidades tratan los aislados de esta manera, por lo que cuando compare los resultados de dos o más de ellos, tenga esto en cuenta.
Estadísticas > Modularidad > Ejecutar
- Ahora, repitamos el proceso con el algoritmo de Louvain, que se implementa mediante la función Modularidad en la pestaña Estadísticas. Esto abrirá un cuadro de diálogo (no se muestra). Tenga en cuenta que incluye un parámetro de ajuste (Resolución), que le permite ajustar si desea obtener menos o más comunidades. Por ahora, haga clic en Aceptar. Esto produce un informe (no se muestra). ¿Cuántas comunidades encontró el algoritmo? ¿Qué es la modularidad?¿Cómo se compara esto con los resultados de Girvan-Newman?
Apariencia > Nodos > Color>Partición > –Escoge un atributo >Modularity Class > Aplicar
- Coloree los nodos usando la partición creada por el algoritmo de Louvain (Clase de modularidad). Debido a que hay más de ~8 comunidades, deberá ajustar la paleta de colores como hicimos en ejercicios anteriores. ¿Louvain asigna a cada aislado en una comunidad separada?
Generate groups by partition
- Ahora colapse la red usando la herramienta Generate groups by partition (Generar grupos por partición). Asegúrese de decirle a Gephi que cree un nuevo espacio de trabajo. Recuerde que los atributos son aspectos no relacionales de las redes. Pueden ser previamente dados (por ejemplo, rol, género, nacionalidad) o pueden ser generados por nuestro análisis de una red. Los algoritmos de agrupación, como los núcleos k y los de detección de comunidad, clasifican actores en varios subgrupos, y la partición de “pertenencia” del subgrupo es un atributo de actor.
- Visualice la red reducida. ¿Aparece algún subgrupo (o subgrupos) más central que otros?